🪄 트랜잭션
데이터를 저장할 때 단순히 파일에 저장해도 되는데, 데이터베이스에 저장하는 이유는 무엇일까?
- 여러가지 이유가 있지만, 가장 대표적인 이유는 바로 데이터베이스는 트랜잭션이라는 개념을 지원하기 때문이다.
- 트랜잭션을 이름 그대로 번역하면 거래라는 뜻이다.
- 쉽게 풀어서 이야기하면, 데이터베이스에서 트랜잭션은 하나의 거래를 안전하게 처리하도록 보장해주는 것을 뜻한다.
그런데 하나의 거래를 안전하게 처리하려면 생각보다 고려해야 할 점이 많다.
- 예를 들어서 A의 5000원을 B에게 계좌이체한다고 생각해보자.
- A의 잔고를 5000원 감소하고, B의 잔고를 5000원 증가해야한다.
5000원 계좌이체
- A의 잔고를 5000원 감소
- B의 잔고를 5000원 증가
계좌이체라는 거래는 이렇게 2가지 작업이 합쳐져서 하나의 작업처럼 동작해야 한다.
- 만약 1번은 성공했는데 2번에서 시스템에 문제가 발생하면 계좌이체는 실패하고,
- A의 잔고만 5000원 감소하는 심각한 문제가 발생한다.
🪄 데이터베이스가 제공하는 트랜잭션 기능을 사용하면
- 1,2 둘다 함께 성공해야 저장하고, 중간에 하나라도 실패하면 거래 전의 상태로 돌아갈 수 있다.
- 만약 1번은 성공했는데 2번에서 시스템에 문제가 발생하면 계좌이체는 실패하고, 거래 전의 상태로 완전히 돌아갈 수 있다.
- 결과적으로 A의 잔고가 감소하지 않는다.
- 모든 작업이 성공해서 데이터베이스에 정상 반영하는 것을 커밋( Commit )이라 하고, 작업 중 하나라도 실패해서 거래 이전으로 되돌리는 것을 롤백( Rollback )이라 한다.
🪄 트랜잭션 ACID
트랜잭션은 ACID 라 하는 원자성(Atomicity), 일관성(Consistency), 격리성(Isolation), 지속성(Durability)을 보장해야 한다.
📕원자성: 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공 하거나 모두 실패해야 한다.
📗일관성: 모든 트랜잭션은 일관성 있는 데이터베이스 상태를 유지해야 한다.
예를 들어 데이터베이스에서 정한 무결성 제약 조건을 항상 만족해야 한다.
📘격리성: 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다.
예를 들어 동시에 같은 데이터를 수정하지 못하도록 해야 한다.
격리성은 동시성과 관련된 성능 이슈로 인해 트랜잭션 격리 수준(Isolation level)을 선택할 수 있다.
📙지속성: 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다.
중간에 시스템에 문제가 발생해도 데이터베이스 로그 등을 사용해서 성공한 트랜잭션 내용을 복구해야 한다.
트랜잭션은 원자성, 일관성, 지속성을 보장한다.
- 문제는 격리성인데 트랜잭션 간에 격리성을 완벽히 보장하려면 트랜잭션을 거의 순서대로 실행해야 한다.
- 이렇게 하면 동시 처리 성능이 매우 나빠진다.
- 이런 문제로 인해 ANSI 표준은 트랜잭션의 격리 수준을 4단계로 나누어 정의했다.
트랜잭션 격리 수준 - Isolation level
- READ UNCOMMITED(커밋되지 않은 읽기)
- READ COMMITTED(커밋된 읽기)
- REPEATABLE READ(반복 가능한 읽기)
- SERIALIZABLE(직렬화 가능)
🔗 데이터베이스 연결 구조와 DB 세션
트랜잭션을 더 자세히 이해하기 위해 데이터베이스 서버 연결 구조와 DB 세션에 대해 알아보자.
데이터베이스 연결 구조 1

- 사용자는 웹 애플리케이션 서버(WAS)나 DB 접근 툴 같은 클라이언트를 사용해서 데이터베이스 서버에 접근할 수 있다. 클라이언트는 데이터베이스 서버에 연결을 요청하고 커넥션을 맺게 된다. 이때 데이터베이스 서버는 내부에 세션이라는 것을 만든다. 그리고 앞으로 해당 커넥션을 통한 모든 요청은 이 세션을 통해서 실행하게 된다.
- 쉽게 이야기해서 개발자가 클라이언트를 통해 SQL을 전달하면 현재 커넥션에 연결된 세션이 SQL을 실행한다.
- 세션은 트랜잭션을 시작하고, 커밋 또는 롤백을 통해 트랜잭션을 종료한다.
- 그리고 이후에 새로운 트랜잭션을 다시 시작할 수 있다.
- 사용자가 커넥션을 닫거나, 또는 DBA(DB 관리자)가 세션을 강제로 종료하면 세션은 종료된다.
데이터베이스 연결 구조 2
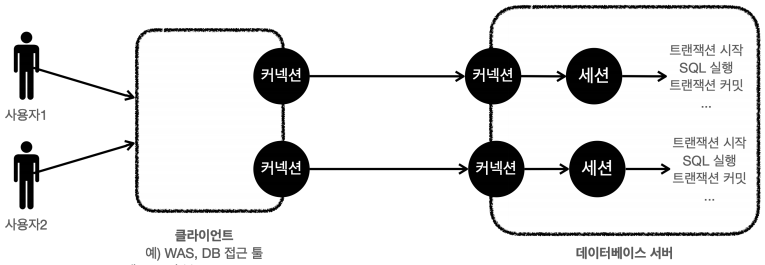
- 커넥션 풀이 10개의 커넥션을 생성하면, 세션도 10개 만들어진다.
🗄️트랜잭션 - DB 예제
지금부터 설명하는 내용은 트랜잭션 개념의 이해를 돕기 위해 예시로 설명하는 것이다.
구체적인 실제 구현 방식은 데이터베이스 마다 다르다.
트랜잭션 사용법
- 데이터 변경 쿼리를 실행하고 데이터베이스에 그 결과를 반영하려면 커밋 명령어인 commit 을 호출하고,
- 결과를 반영하고 싶지 않으면 롤백 명령어인 rollback 을 호출하면 된다
- 커밋을 호출하기 전까지는 임시로 데이터를 저장하는 것이다. 따라서 해당 트랜잭션을 시작한 세션(사용자)에게만 변경 데이터가 보이고 다른 세션(사용자)에게는 변경 데이터가 보이지 않는다.
- 등록, 수정, 삭제 모두 같은 원리로 동작한다. 앞으로는 등록, 수정, 삭제를 간단히 변경이라는 단어로 표현하겠다
기본 데이터

- 세션1, 세션2 둘다 가운데 있는 기본 테이블을 조회하면 해당 데이터가 그대로 조회된다.
세션1 신규 데이터 추가

- 세션1은 트랜잭션을 시작하고 신규 회원1, 신규 회원2를 DB에 추가했다. 아직 커밋은 하지 않은 상태이다.
- 새로운 데이터는 임시 상태로 저장된다.
- 세션1은 select 쿼리를 실행해서 본인이 입력한 신규 회원1, 신규 회원2를 조회할 수 있다.
- 세션2는 select 쿼리를 실행해도 신규 회원들을 조회할 수 없다. 왜냐하면 세션1이 아직 커밋을 하지 않았기 때문이다.
🤔 커밋하지 않은 데이터를 다른 곳에서 조회할 수 있으면 어떤 문제가 발생할까?
- 예를 들어서 커밋하지 않는 데이터가 보인다면, 세션2는 데이터를 조회했을 때 신규 회원1, 2가 보일 것이다. 따라서 세션 2는 신규 회원1, 신규 회원2가 있다고 가정하고 어떤 로직을 수행할 수 있다. 그런데 세션1이 롤백을 수행하면 신규 회원1, 신규 회원2의 데이터가 사라지게 된다. 따라서 데이터 정합성에 큰 문제가 발생한다.
- 세션2에서 세션1이 아직 커밋하지 않은 변경 데이터가 보이다면, 세션1이 롤백 했을 때 심각한 문제가 발생할 수 있다. 따라서 커밋 전의 데이터는 다른 세션에서 보이지 않는다.
세션1 신규 데이터 추가 후 commit

- 세션1이 신규 데이터를 추가한 후에 commit 을 호출했다.
- commit 으로 새로운 데이터가 실제 데이터베이스에 반영된다. 데이터의 상태도 임시 ➔ 완료로 변경되었다.
- 이제 다른 세션에서도 회원 테이블을 조회하면 신규 회원들을 확인할 수 있다.
세션1 신규 데이터 추가 후 rollback

- 세션1이 신규 데이터를 추가한 후에 commit 대신에 rollback 을 호출했다.
- 세션1이 데이터베이스에 반영한 모든 데이터가 처음 상태로 복구된다.
- 수정하거나 삭제한 데이터도 rollback 을 호출하면 모두 트랜잭션을 시작하기 직전의 상태로 복구된다.
🗄️트랜잭션 - 자동 커밋, 수동 커밋
자동 커밋, 수동 커밋에 대해 알아보자.
스키마는 다음과 같다.
drop table member if exists;
create table member (
member_id varchar(10),
money integer not null default 0,
primary key (member_id)
);
✅ 자동 커밋
트랜잭션을 사용하려면 먼저 자동 커밋과 수동 커밋을 이해해야 한다.
- 자동 커밋으로 설정하면 각각의 쿼리 실행 직후에 자동으로 커밋을 호출한다.
- 따라서 커밋이나 롤백을 직접 호출하지 않아도 되는 편리함이 있다.
- 하지만 쿼리를 하나하나 실행할 때 마다 자동으로 커밋이 되어버리기 때문에 우리가 원하는 트랜잭션 기능을 제대로 사용할 수 없다.
자동 커밋 설정
set autocommit true; //자동 커밋 모드 설정
insert into member(member_id, money) values ('data1',10000); //자동 커밋
insert into member(member_id, money) values ('data2',10000); //자동 커밋- 따라서 commit , rollback 을 직접 호출하면서 트랜잭션 기능을 제대로 수행하려면 자동 커밋을 끄고 수동 커밋을 사용해야 한다.
수동 커밋 설정
set autocommit false; //수동 커밋 모드 설정
insert into member(member_id, money) values ('data3',10000);
insert into member(member_id, money) values ('data4',10000);
commit; //수동 커밋- 보통 자동 커밋 모드가 기본으로 설정된 경우가 많기 때문에, 수동 커밋 모드로 설정하는 것을 트랜잭션을 시작한다고 표현할 수 있다.
- 수동 커밋 설정을 하면 이후에 꼭 commit , rollback 을 호출해야 한다.
참고로 수동 커밋 모드나 자동 커밋 모드는 한번 설정하면 해당 세션에서는 계속 유지된다.
중간에 변경하는 것은 가능하다.
📝 정리
원자성
- 트랜잭션 내에서 실행한 작업들은 마치 하나의 작업인 것처럼 모두 성공 하거나 모두 실패해야 한다.
- 트랜잭션의 원자성 덕분에 여러 SQL 명령어를 마치 하나의 작업인 것 처럼 처리할 수 있었다.
- 성공하면 한번에 반영하고, 중간에 실패해도 마치 하나의 작업을 되돌리는 것 처럼 간단히 되돌릴 수 있다.
오토 커밋
- 만약 오토 커밋 모드로 동작하는데, 계좌이체 중간에 실패하면 어떻게 될까?
- 쿼리를 하나 실행할 때 마다 바로바로 커밋이 되어버리기 때문에 회원의 돈만 2000원 줄어드는 심각한 문제가 발생한다.
트랜잭션 시작
- 따라서 이런 종류의 작업은 꼭 수동 커밋 모드를 사용해서 수동으로 커밋, 롤백 할 수 있도록 해야 한다.
- 보통 이렇게 자동 커밋 모드에서 수동 커밋 모드로 전환 하는 것을 트랜잭션을 시작한다고 표현한다.
'Spring' 카테고리의 다른 글
| [Spring DB] 트랜잭션 적용 (0) | 2024.08.09 |
|---|---|
| [Spring DB] DB 락 (0) | 2024.08.09 |
| [Spring DB] 커넥션 풀과 데이터 소스 (1) | 2024.08.08 |
| [Spring DB] JDBC 를 이용하여 CRUD 구현하기 (0) | 2024.08.07 |
| [Spring] 로깅 간단히 알아보기 (0) | 2024.07.19 |



