목차
- 인터페이스 도입
- 의존성 주입
- 컴파일 타임, 런타임 의존관계
- 리스트 성능 비교
리스트 추상화 - 인터페이스 도입
다형성과 OCP 원칙을 가장 잘 활용할 수 있는 곳 중에 하나가 바로 자료 구조이다.
자료 구조에 다형성과 OCP 원칙이 어떻게 적용되는지 알아보자.
List 자료 구조
순서가 있고, 중복을 허용하는 자료 구조를 리스트( List )라 한다.
우리가 지금까지 만든 MyArrayList 와 MyLinkedList 는 내부 구현만 다를 뿐 같은 기능을 제공하는 리스트이다.
물론 내부 구현이 다르기 때문에 상황에 따라 성능은 달라질 수 있다.
핵심은 사용자 입장에서 보면 같은 기능을 제공한다는 것이다.
이 둘의 공통 기능을 인터페이스로 뽑아서 추상화하면 다형성을 활용한 다양한 이득을 얻을 수 있다

같은 기능을 제공하는 메서드를 MyList 인터페이스로 뽑아보자.
public interface MyList<E> {
int size();
void add(E e);
void add(int index, E e);
E get(int index);
E set(int index, E element);
E remove(int index);
int indexOf(E o);
}public class MyArrayList<E> implements MyList<E>{
private static final int DEFAULT_CAPACITY = 5;
private Object[] elementData;
private int size = 0;
public MyArrayList() {
elementData = new Object[DEFAULT_CAPACITY];
}
public MyArrayList(int initialCapacity) {
elementData = new Object[initialCapacity];
}
@Override
public int size() {
return size;
}
@Override
public void add(E e) {
if (size == elementData.length) {
grow();
}
elementData[size] = e;
size++;
}
@Override
public void add(int index, E e) {
if (size == elementData.length) {
grow();
}
// 데이터 이동
shiftRightFrom(index);
elementData[index] = e;
size++;
}
private void shiftRightFrom(int index) {
for (int i = size; i > index; i--) {
elementData[i] = elementData[i - 1];
}
}
private void grow() {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity * 2;
elementData = Arrays.copyOf(elementData, newCapacity);
}
@Override
public E get(int index) {
return (E) elementData[index];
}
@Override
public E set(int index, E element) {
E oldValue = get(index);
elementData[index] = element;
size--;
elementData[size] = null;
return oldValue;
}
@Override
public E remove(int index) {
E oldValue = get(index);
shiftLeftFrom(index);
// 데이터 이동
size--;
elementData[size] = null;
return oldValue;
}
private void shiftLeftFrom(int index) {
for (int i = index; i < size - 1; i++) {
elementData[i] = elementData[i + 1];
}
}
@Override
public int indexOf(E e) {
for (int i = 0; i < size; i++) {
if (e.equals(elementData[i])) {
return i;
}
}
return -1;
}
@Override
public String toString() {
return Arrays.toString(Arrays.copyOf(elementData, size)) +
" size = " + size + ", capacity = " + elementData.length;
}
}public class MyLinkedList<E> implements MyList<E>{
private Node<E> first; // 첫 노드의 위치를 가르킨다.
private int size = 0;
@Override
public void add(E e) {
Node<E> newNode = new Node<>(e);
if (first == null) {
first = newNode;
} else {
Node<E> lastNode = getLastNode();
lastNode.next = newNode;
}
size++;
}
@Override
public void add(int index, E e) {
Node<E> newNode = new Node<>(e);
if (index == 0) {
newNode.next = first;
first = newNode;
} else {
Node<E> prev = getNode(index - 1);
newNode.next = prev.next;
prev.next = newNode;
}
size++;
}
private Node<E> getLastNode() {
Node<E> x = first;
while (x.next != null) {
x = x.next;
}
return x;
}
@Override
public E set(int index, E element) {
Node<E> x = getNode(index);
E oldValue = x.item;
x.item = element;
return oldValue;
}
@Override
public E remove(int index) {
Node<E> removeNode = getNode(index);
E removeItem = removeNode.item;
if (index == 0) {
first = removeNode.next;
} else {
Node<E> prev = getNode(index - 1);
prev.next = removeNode.next;
}
removeNode.next = null;
removeNode.item = null;
size--;
return removeItem;
}
@Override
public E get(int index) {
Node<E> x = getNode(index);
return x.item;
}
private Node<E> getNode(int index) {
Node<E> x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
@Override
public int indexOf(E o) {
int index = 0;
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
return index;
}
index++;
}
return -1;
}
public int size() {
return size;
}
@Override
public String toString() {
return "MyLinkedListV2{" +
"first=" + first +
", size=" + size +
'}';
}
private static class Node<E> {
E item;
Node<E> next;
public Node(E item) {
this.item = item;
}
@Override
public String toString() { // 문자열을 결합할 땐 가변문자열을 쓰자!
StringBuilder sb = new StringBuilder();
Node<E> x = this;
sb.append("[");
while (x != null) {
sb.append(x.item);
if (x.next != null) {
sb.append("->");
}
x = x.next;
}
sb.append("]");
return sb.toString();
}
}
}
의존관계 주입
데이터를 앞에서 추가하거나 삭제하는 일이 많다면 MyArrayList 보다는 MyLinkedList 를 사용하는 것이 훨씬 효율적이다.
데이터를 앞에서 추가하거나 삭제할 때 빅오 비교
- MyArrayList : O(n)
- MyLinkedList : O(1)
MyArrayList 사용 예시
public class BatchProcessor {
private final MyArrayList<Integer> list = new MyArrayList<>(); //코드 변경
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}
MyLinkedList 사용 예시
public class BatchProcessor {
private final MyLinkedList<Integer> list = new MyLinkedList<>(); //코드 변경
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}
BatchProcessor 는 구체적인 MyArrayList 또는 MyLinkedList 를 사용하고 있다.
이것을 BatchProcessor 가 구체적인 클래스에 의존한다고 표현한다.
이렇게 구체적인 클래스에 직접 의존하면 MyArrayList 를 MyLinkedList 로 변경할 때 마다
여기에 의존하는 BatchProcessor 의 코드도 함께 수정해야 한다.
BatchProcessor 가 구체적인 클래스에 의존하는 대신 추상적인 MyList 인터페이스에 의존하는 방법도 있다.
MyList 인터페이스 사용 예시
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
public void logic(int size) {
for (int i = 0; i < size; i++) {
list.add(0, i); //앞에 추가
}
}
}main() {
new BatchProcessor(new MyArrayList()); //MyArrayList를 사용하고 싶을 때
new BatchProcessor(new MyLinkedList()); //MyLinkedList를 사용하고 싶을 때
}
그리고 BatchProcessor 를 생성하는 시점에 생성자를 통해 원하는 리스트 전략(알고리즘)을 선택해서 전달하면 된다.
이렇게 하면 MyList 를 사용하는 클라이언트 코드인 BatchProcessor 를 전혀 변경하지 않고, 원하는 리스트 전략을
런타임에 지정할 수 있다. 정리하면 다형성과 추상화를 활용하면 BatchProcessor 코드를 전혀 변경하지 않고 리스트 전략(알고리즘)을 MyArrayList 에서 MyLinkedList 로 변경할 수 있다.
public class BatchProcessor {
private final MyList<Integer> list;
public BatchProcessor(MyList<Integer> list) {
this.list = list;
}
public void logic(int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("크기: " + size + ", 계산 시간: " + (endTime - startTime) + " ms");
}- logic(int size) 메서드는 매우 복잡한 비즈니스 로직을 다룬다고 가정하자.
- 이 메서드는 list 의 앞 부분에 데이터를 추가한다.
- 어떤 MyList list 의 구현체를 선택할 지는 실행 시점에 생성자를 통해서 결정한다.
- 생성자를 통해서 MyList 구현체가 전달된다.
- MyArrayList 의 인스턴스가 들어올 수도 있고, MyLinkedList 의 인스턴스가 들어올 수도 있다.
- 이것은 BatchProcessor 의 외부에서 의존관계가 결정되어서 BatchProcessor 인스턴스에 들어오는 것같다.
- 마치 의존관계가 외부에서 주입되는 것 같다고 해서 이것을 의존관계 주입이라 한다.
- 참고로 생성자를 통해서 의존관계를 주입했기 때문에 생성자 의존관계 주입이라 한다.
의존관계 주입
- Dependency Injection, 줄여서 DI라고 부른다. 의존성 주입이라고도 부른다.
public class BatchProcessorMain {
public static void main(String[] args) {
MyArrayList<Integer> list = new MyArrayList<>();
BatchProcessor processor = new BatchProcessor(list);
processor.logic(100000);
MyLinkedList<Integer> list2 = new MyLinkedList<>();
BatchProcessor processor2 = new BatchProcessor(list2);
processor2.logic(100000);
}
}크기: 100000, 계산 시간: 11721 ms
크기: 100000, 계산 시간: 7 ms- BatchProcessor 의 생성자에 MyArrayList 를 사용할지, MyLinkedList 를 사용할지 결정해서 넘겨야한다.
- 이후에 processor.logic() 을 호출하면 생성자로 넘긴 자료 구조를 사용해서 실행한다.
MyLinkedList 를 사용한 덕분에 O(n) O(1)로 훨씬 더 성능이 개선 된 것을 확인할 수 있다.
데이터가 증가할수록 성능의 차이는 더 벌어진다.
컴파일 타임, 런타임 의존관계
의존관계는 크게 컴파일 타임 의존관계와 런타임 의존관계로 나눌 수 있다.
- 컴파일 타임(compile time): 코드 컴파일 시점을 뜻한다.
- 런타임(runtime): 프로그램 실행 시점을 뜻한다.
컴파일 타임 의존관계 vs 런타임 의존관계

- 컴파일 타임 의존관계는 자바 컴파일러가 보는 의존관계이다.
- 클래스에 모든 의존관계가 다 나타난다.
- 쉽게 이야기해서 클래스에 바로 보이는 의존관계이다.
- 그리고 실행하지 않은 소스 코드에 정적으로 나타나는 의존관계이다.
- BatchProcessor 클래스를 보면 MyList 인터페이스만 사용한다.
- 코드 어디에도 MyArrayList 나 MyLinkedList 같은 정보는 보이지 않는다.
- 따라서 BatchProcessor 는 MyList 인터페이스에만 의존한다.
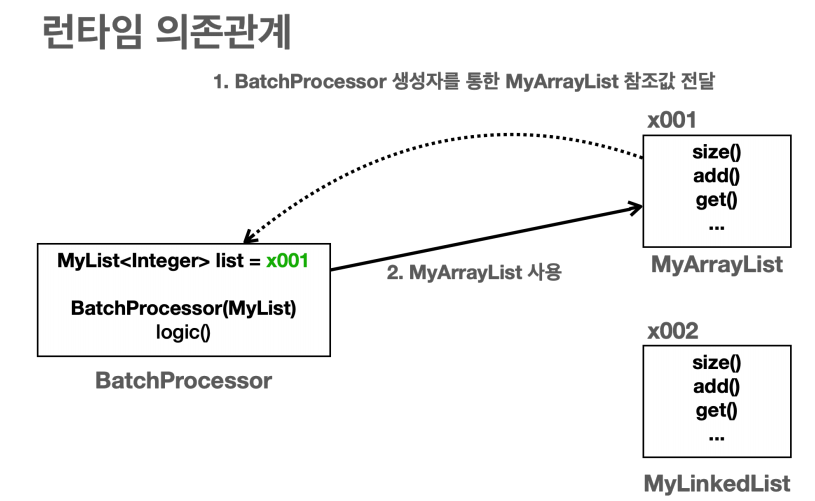
- 런타임 의존관계는 실제 프로그램이 작동할 때 보이는 의존관계다.
- 주로 생성된 인스턴스와 그것을 참조하는 의존관계이다.
- 쉽게 이야기해서 프로그램이 실행될 때 인스턴스 간에 의존관계로 보면 된다.
- 런타임 의존관계는 프로그램 실행 중에 계속 변할 수 있다.
정리
- MyList 인터페이스의 도입으로 같은 리스트 자료구조를 그대로 사용하면서 원하는 구현을 변경할 수 있게 되었다.
- BatchProcessor 에서 다음과 같이 처음부터 MyArrayList 를 사용하도록 컴파일 타임 의존관계를 지정했다면 이후에 MyLinkedList 로 수정하기 위해서는 BatchProcessor 의 코드를 변경해야 한다.
- BatchProcessor 클래스는 구체적인 MyArrayList 나 MyLinkedList 에 의존하는 것이 아니라 추상적인 MyList 에 의존한다. 따라서 런타임에 MyList 의 구현체를 얼마든지 선택할 수 있다.
- BatchProcessor 에서 사용하는 리스트의 의존관계를 클래스에서 미리 결정하는 것이 아니라, 런타임에 객체
를 생성하는 시점으로 미룬다. 따라서 런타임에 MyList 의 구현체를 변경해도 BatchProcessor 의 코드는 전
혀 변경하지 않아도 된다. - 이렇게 생성자를 통해 런타임 의존관계를 주입하는 것을 생성자 의존관계 주입 또는 줄여서 생성자 주입이라 한다.
- 자바 기본편에서 학습한 OCP 원칙을 지켰다. 클라이언트 코드의 변경 없이, 구현 알고리즘인 MyList 인터페이스의 구현을 자유롭게 확장할 수 있다.
- 클라이언트 클래스는 컴파일 타임에 추상적인 것에 의존하고, 런타임에 의존 관계 주입을 통해 구현체를 주입받아
사용함으로써, 이런 이점을 얻을 수 있다.
전략 패턴(Strategy Pattern)
디자인 패턴 중에 가장 중요한 패턴을 하나 뽑으라고 하면 전략 패턴을 뽑을 수 있다. 전략 패턴은 알고리즘을 클
라이언트 코드의 변경 없이 쉽게 교체할 수 있다. 방금 설명한 코드가 바로 전략 패턴을 사용한 코드이다.
MyList 인터페이스가 바로 전략을 정의하는 인터페이스가 되고, 각각의 구현체인 MyArrayList ,
MyLinkedList 가 전략의 구체적인 구현이 된다. 그리고 전략을 클라이언트 코드( BatchProcessor )의 변경
없이 손쉽게 교체할 수 있다.
리스트의 성능 비교
public class MyListPerformanceTest {
public static void main(String[] args) {
int size = 50000;
System.out.println("== MyArrayList 추가 ==");
addFirst(new MyArrayList<>(), size);
addMid(new MyArrayList<>(), size); // 찾는데 O(1), 데이터 추가(밀기) O(n)
MyArrayList<Integer> arrayList = new MyArrayList<>(); // 조회용 데이터로 사용
addLast(arrayList, size); // 찾는데 O(1), 데이터 추가(밀기) O(1)
int loop = 10000;
System.out.println("== MyArrayList 조회 ==");
getIndex(arrayList, loop, 0);
getIndex(arrayList, loop, size / 2);
getIndex(arrayList, loop, size - 1);
System.out.println("== MyArrayList 검색 ==");
search(arrayList, loop, 0);
search(arrayList, loop, size / 2);
search(arrayList, loop, size - 1);
System.out.println("== MyLinkedList 추가 ==");
addFirst(new MyLinkedList<>(), size);
addMid(new MyLinkedList<>(), size); // 찾는데 O(n), 데이터 추가 O(1)
MyLinkedList<Integer> linkedList = new MyLinkedList<>(); // 조회용 데이터로 사용
addLast(linkedList, size); // 찾는데 O(n), 데이터 추가 O(1)
System.out.println("== MyLinkedList 조회 ==");
getIndex(linkedList, loop, 0);
getIndex(linkedList, loop, size / 2);
getIndex(linkedList, loop, size - 1);
System.out.println("== MyLinkedList 검색 ==");
search(linkedList, loop, 0);
search(linkedList, loop, size / 2);
search(linkedList, loop, size - 1);
}
private static void addFirst(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(0, i);
}
long endTime = System.currentTimeMillis();
System.out.println("앞에 추가 - 크기: " + size + "계산 시간: " + (endTime - startTime) + " ms");
}
private static void addMid(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i / 2, i);
}
long endTime = System.currentTimeMillis();
System.out.println("평균 추가 - 크기: " + size + "계산 시간: " + (endTime - startTime) + " ms");
}
private static void addLast(MyList<Integer> list, int size) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < size; i++) {
list.add(i);
}
long endTime = System.currentTimeMillis();
System.out.println("평균 추가 - 크기: " + size + "계산 시간: " + (endTime - startTime) + " ms");
}
private static void getIndex(MyList<Integer> list, int loop, int index) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < loop; i++) {
list.get(index);
}
long endTime = System.currentTimeMillis();
System.out.println("index: " + index + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + " ms");
}
private static void search(MyList<Integer> list, int loop, int findValue) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < loop; i++) {
list.indexOf(findValue);
}
long endTime = System.currentTimeMillis();
System.out.println("findValue: " + findValue + ", 반복: " + loop + ", 계산 시간: " + (endTime - startTime) + "ms"); }
}== MyArrayList 추가 ==
앞에 추가 - 크기: 50000계산 시간: 2913 ms
평균 추가 - 크기: 50000계산 시간: 1191 ms
평균 추가 - 크기: 50000계산 시간: 3 ms
== MyArrayList 조회 ==
index: 0, 반복: 10000, 계산 시간: 0 ms
index: 25000, 반복: 10000, 계산 시간: 0 ms
index: 49999, 반복: 10000, 계산 시간: 0 ms
== MyArrayList 검색 ==
findValue: 0, 반복: 10000, 계산 시간: 1ms
findValue: 25000, 반복: 10000, 계산 시간: 221ms
findValue: 49999, 반복: 10000, 계산 시간: 356ms
== MyLinkedList 추가 ==
앞에 추가 - 크기: 50000계산 시간: 4 ms
평균 추가 - 크기: 50000계산 시간: 1186 ms
평균 추가 - 크기: 50000계산 시간: 2569 ms
== MyLinkedList 조회 ==
index: 0, 반복: 10000, 계산 시간: 1 ms
index: 25000, 반복: 10000, 계산 시간: 419 ms
index: 49999, 반복: 10000, 계산 시간: 810 ms
== MyLinkedList 검색 ==
findValue: 0, 반복: 10000, 계산 시간: 2ms
findValue: 25000, 반복: 10000, 계산 시간: 589ms
findValue: 49999, 반복: 10000, 계산 시간: 1162ms
시간 복잡도와 실제 성능
이론적으로 MyLinkedList 가 평균 추가(중간 삽입)에 있어 더 효율적일 수 있지만, 현대 컴퓨터 시스템의
메모리 접근 패턴, CPU 캐시 최적화 등을 고려할 때 MyArrayList 가 실제 사용 환경에서 더 나은 성능을 보여주는
경우가 많다.
배열 리스트 vs 연결 리스트
대부분의 경우 배열 리스트가 성능상 유리하다. 이런 이유로 실무에서는 주로 배열 리스트를 기본으로 사용한다.
만약 데이터를 앞쪽에서 자주 추가하거나 삭제할 일이 있다면 연결 리스트를 고려하자.
'복습' 카테고리의 다른 글
| [Java 복습] 직접 구현해보는 Set (feat. 해시 알고리즘) (0) | 2024.05.17 |
|---|---|
| [Java 복습] 자바 리스트의 모든 것 (0) | 2024.05.16 |
| [Java 복습] 직접 구현해보는 LinkedList (0) | 2024.05.16 |
| [Java 복습] 노드란? 노드 연결, 기능구현 해보기 (0) | 2024.05.13 |
| [Java 복습] 직접 구현해보는 ArrayList (0) | 2024.05.13 |



